
Power Automate Desktop
「ブラウザー自動化」を使いこなす~Webデータ抽出~
日々の業務でインターネットを全く使わないというのは、これだけネット社会が進んだ現代においてそう多くはないでしょう。RPAのシナリオを作る際もWebサイトを全く利用しないとなるとできることの幅がかなり限られてしまいます。このページではそんなWebサイトを表示させる機能を持つ「ブラウザー」を自動化させるアクションについて見ていきます。Power Automate Desktopでは「ブラウザー」を扱うアクションが数多く用意されており、メニューを開いてみると直下のアクションが13種類、更にプルダウンメニューが2種類用意されています。このページでは「Webデータ抽出」のプルダウンメニューにあるアクションについてひとつひとつ動きを確認していきましょう。
(なお、2022/8/4執筆時点でのアクション数であり、今後、利用できるオプションが増える可能性があります。)
1. Webページからデータを抽出する

「Webページからデータ抽出する」アクションを利用すると、指定したWebサイトから表データなどを取得できるようになります。抽出したデータは変数として保存されるかExcelに保存されます。
設定画面ではまずブラウザーインスタンスを選択します。選択可能なインスタンスがない場合は、「新しい(ブラウザー名)を起動」アクションなどを利用して生成しましょう。「抽出時にデータを処理する」をONにすると、処理は遅くなりますが、データを整形して変数やExcelに格納してくれます。「タイムアウト」ではタイムアウトさせる秒数を設定できます。「データ保存モード」で変数として保存するかExcelとして保存するか選択します。これですべての準備完了と思って保存ボタンを押しても実はエラーが出ます。抽出パラメータを設定してくださいというエラーメッセージが出ているはずです。
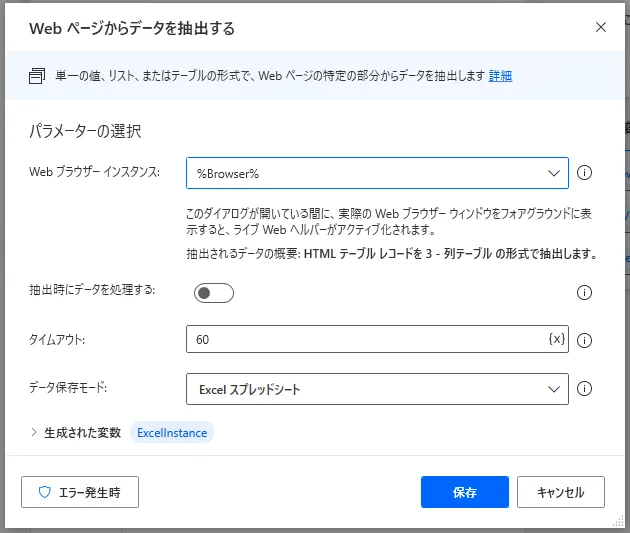
実はこのアクションではあらかじめ対象のブラウザーインスタンスを最前面で起動しておいて、抽出するデータの詳細を選択する必要があります。設定画面を開いた状態で、インスタンスを最前面にしてください。下図のようにデザイン画面が閉じて、「ライブWebヘルパー」画面が現われればOKです。
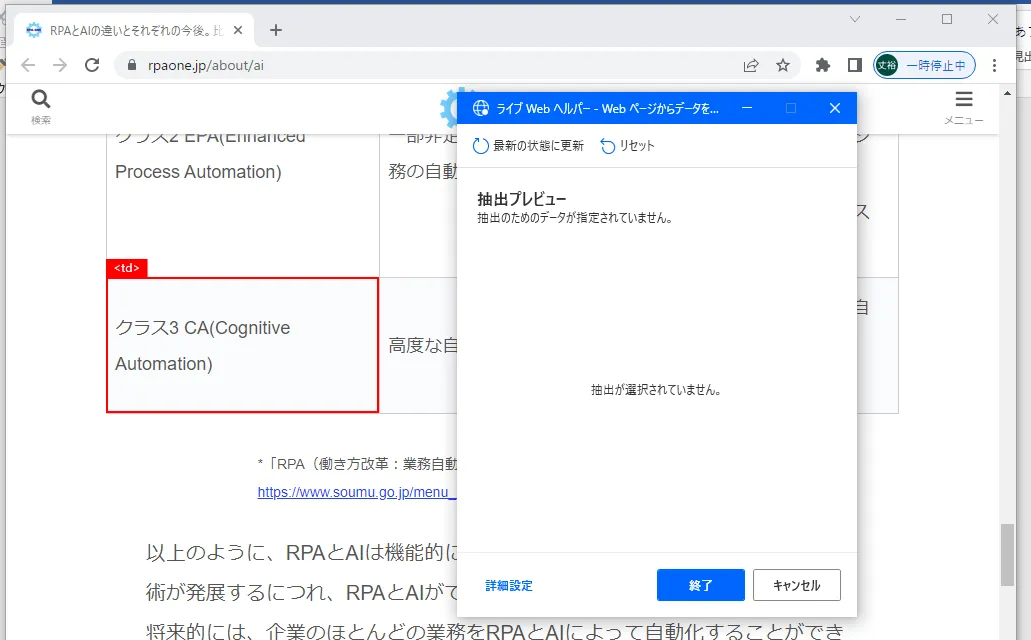
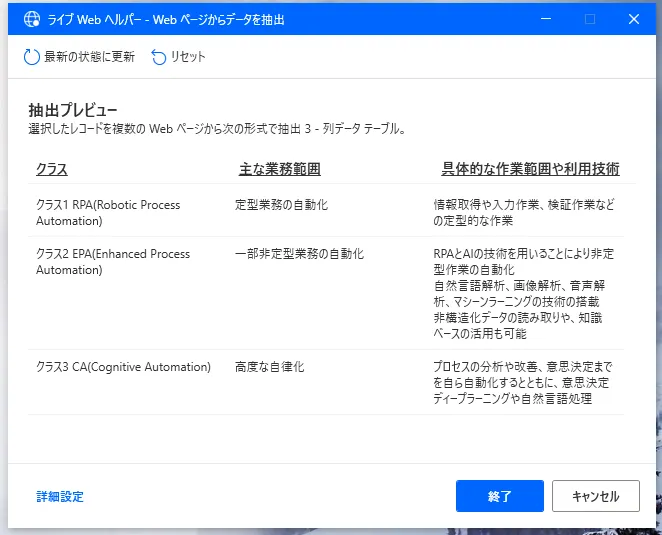
抽出モードになるとマウスでホバーしたUIが赤い枠線で囲まれます。抽出したいデータを選択したら右クリックを押します。そうすると抽出方法として、「要素の値を抽出」「HTMLテーブル全体を抽出する」「要素をページャーとして設定」「親UI要素の選択」の4つから選択できます。「要素の値を抽出」では詳細からいくつかの抽出したい値を取得できます。1回選択するだけだと単純な変数に格納されますが、2回以上選択すると「1行×選択数列」のデータテーブル型の変数に格納されます。「親UI要素の選択」では選択したUIの親要素に選択が入れ替わります。「HTMLテーブル全体を抽出する」ではテーブル全体を一度に取得できるので使い勝手がとても良いです。下図の場合だと、列名のついた「3行×3列」のテーブル型変数が取得できます。

データ抽出の選択ができると下図のようにプレビュー画面に抽出されたデータが追加されています。
表のデータ数が表示最大件数を越える場合に2ページ目、3ページ目・・・と表下部にページが現われることがあります。これを「ページャー」と呼びますが、「要素をページャーとして設定」を利用すると、指定した要素をページャーとして扱うことができます。設定画面では下図のようにいくつかのページャーに関するパラメータが追加されます。「データの抽出元」では読み込むページ数を設定することができます。「最初のみ」にすると、次の「処理するWebページの最大数」から何ページ読み込ませるかを設定でき、「すべてを使用できます」を使用するとすべてのページデータを読み込ませることができます。

設定が終わったら実行してみます。Excel画面と変数に格納した場合ではそれぞれ下図のように値が格納されています。


2. Webページ上の詳細を取得します

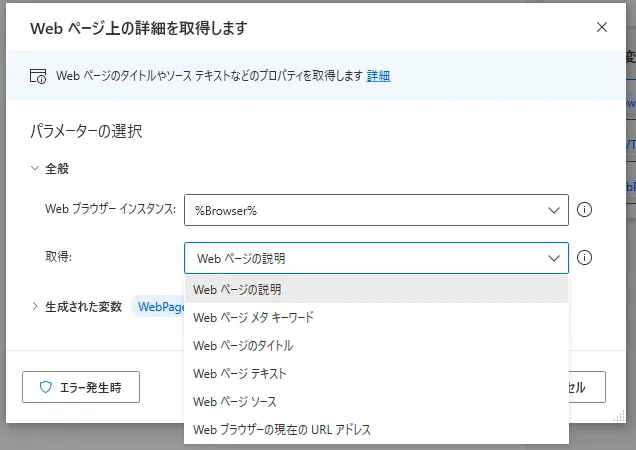
「Webページ上の詳細を取得します」アクションを利用すると、Webページ上の情報を取得することができます。設定画面を開くとパラメータが2つあります。まずは取得したいブラウザーインスタンスを選択してください。選択するインスタンスがない場合は先に生成する必要があります。次に取得するデータの種類を選択します。「Webページの説明」を選ぶとヘッダータグにあるメタディスクリプションを取得できます。メタディスクリプションはGoogleなどでの検索結果画面で表示されるサイトの説明に使われています。「メタキーワード」はヘッダータグにあるメタキーワードを取得できます。SEO対策などに使われたりしましたが、最近はメタキーワードを入れても入れなくてもそんなに検索順位は変わらないみたいです。「Webページのタイトル」はヘッダータグにあるタイトルを取得します。画面上部のウィンドウタブに表示される内容です。「Webページのテキスト」は指定したページのテキストをすべて取得します。「Webページ ソース」はソースコードを取得できます。「Webブラウザーの現在のURLアドレス」ではWebページのURLを取得できます。
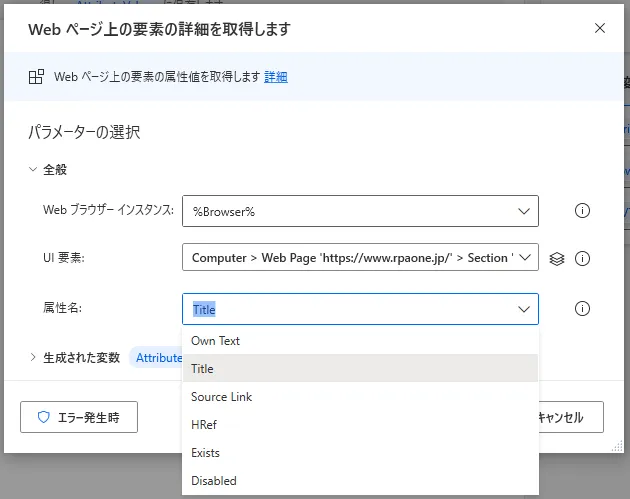
3. Webページ上の要素の詳細を取得します

「Webページ上の要素の詳細を取得します」アクションを利用すると、Webページ上の指定した要素の情報を取得することができます。設定画面を開くとパラメータが3つあります。まずは取得したいブラウザーインスタンスを選択してください。選択するインスタンスがない場合は先に生成する必要があります。次にUI要素を指定します。情報を取得したいUI要素を選択してください。最後に取得するデータの種類を選択します。「Own Text」は指定したUI要素のテキストを取得します。「Title」はタグのtitle属性(マウスを合わせた時に出てくる説明文。title属性が設定されていない場合も結構あります。)を取得します。「Source Link」では画像などのタグにあるsrc属性を取得します。src属性は画像などの保存場所があるパスが設定されています。「HRef」はリンク先のURLを取得します。「Exists」は指定したUI要素が存在するかどうかを判定します。「Disabled」は指定したUIが有効かどうかを判定します。テキストボックスの入力可否を取得したい場合などに使用します。
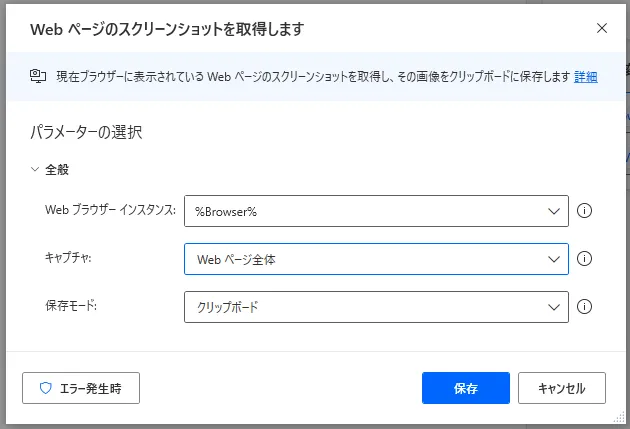
4. Webページのスクリーンショットを取得します

「Webページのスクリーンショットを取得」アクションを使うと、指定したWebページ全体やその中のUI要素のキャプチャを取得することができます。設定画面での主なパラメータは3つです。最初にブラウザーインスタンスを選択します。選択するインスタンスがない場合は先に生成する必要があります。次にWebページ全体のキャプチャをするか、UI要素のキャプチャをするか選択できます。UI要素のキャプチャをする場合はUI要素も追加で選択します。最後に保存方法をクリップボードで保存するかファイルに保存するか選びます。ファイルに保存する場合は保存する画像ファイルを選択します。
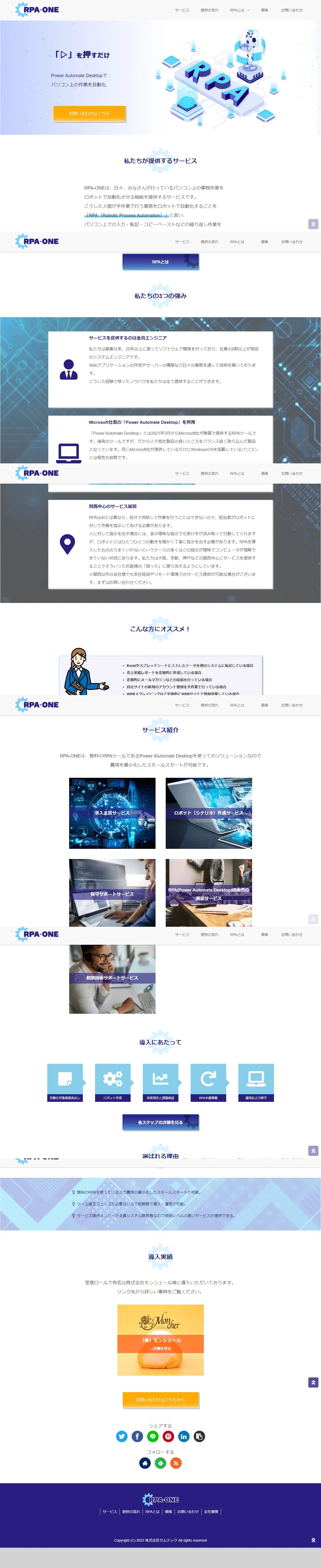
上図の設定でRPA-ONEのTOPページをキャプチャしてみました。結果は以下のようになります。おそらくユーザーと同じように画面をRPAにスクロールさせて逐一キャプチャしているので、ヘッダーなどのナビゲーションが画面に固定されていると、キャプチャ画像にナビゲーションが繰り返し入ってしまうようです。今後の改善に期待です。
以上、「ブラウザー自動化」の「Webデータ抽出」アクションについても解説でした。RPAでWebサイトの自動化ができるようになると、自動化のできる幅が一気に広がります。他のアクションなどと組み合わせてWebサイトの操作も自動化できるようになろう。
→「Power Automate Desktop」の他の操作も見る執筆者プロフィール

伊藤 丈裕
(株)サムテックのシステムエンジニア。応用情報技術者資格保有。
27歳の時、営業から完全未経験で転職。開発とWebマーケティングを担当。得意言語はJavaとJavaScript。